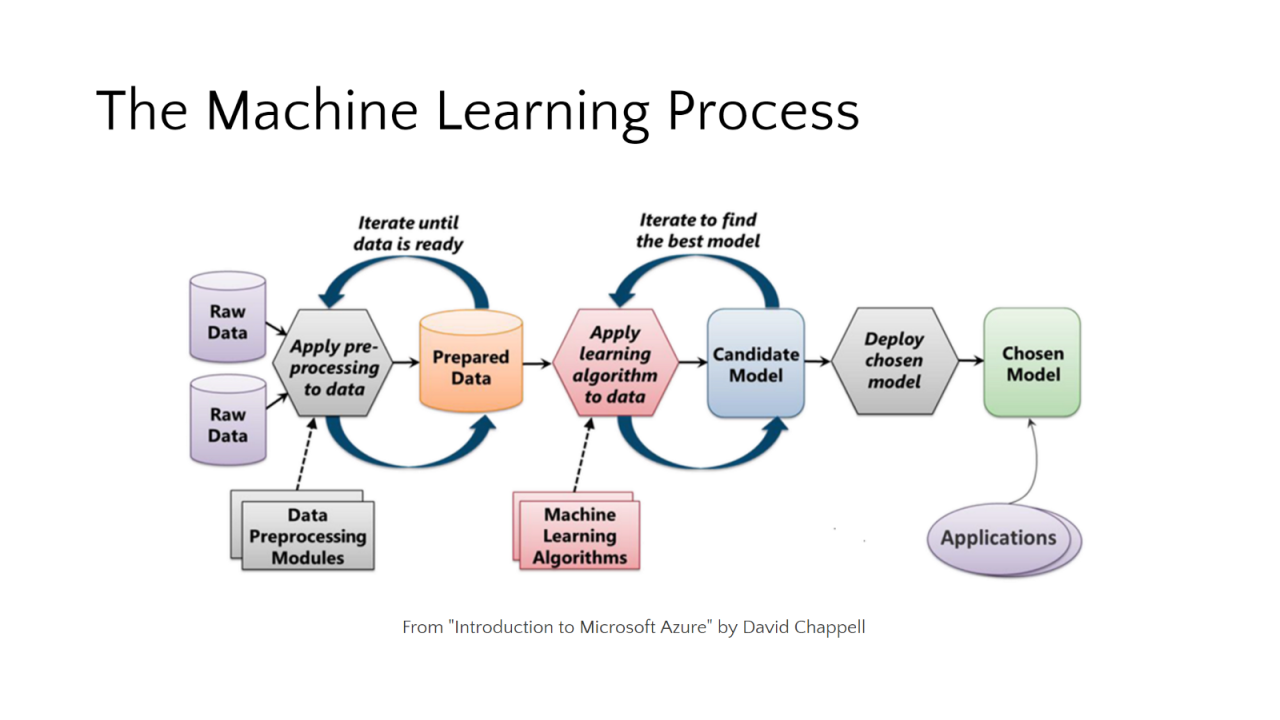
Machine learning has become an essential part of many industries, including healthcare, finance, and retail. The goal of machine learning is to identify patterns in data and use them to make accurate predictions or take actions. However, to achieve this, it is crucial to have high-quality data that has been correctly prepared for analysis.
What is Data Preparation?
Data preparation is the process of cleaning and transforming raw data into a format that is suitable for analysis. It is the initial and essential step of the machine learning process. It involves several steps, including:
- Removing irrelevant data
- Handling missing values
- Dealing with outliers
- Transforming data into a suitable format
- Splitting data into training and testing sets
Each of these steps is crucial for ensuring that the data is ready to be used in a machine learning model. If the data is not correctly prepared, it can lead to inaccurate or unreliable predictions.
Why is Data Preparation Important?
The following are some reasons why data preparation is so important in machine learning:
- Garbage In, Garbage Out
The quality of the data you put into your machine learning model determines the quality of the results you will get. Poor-quality data leads to unreliable and inaccurate predictions. Therefore, it is crucial to ensure that the data is of high quality and that any irrelevant data is removed.
- Improved Accuracy
Data preparation helps to improve the accuracy and reliability of machine learning models. This is achieved by removing noise and inconsistencies from the data. The resulting data is then used to train the model, leading to more accurate predictions.
- More Efficient Models
Proper data preparation can lead to more efficient machine learning models. By removing irrelevant data and handling missing values, you can reduce the amount of processing power required to train the model. This can result in a faster and more efficient machine learning model.
Best Practices for Data Preparation
Here are some best practices to keep in mind when preparing data for machine learning:
- Understand Your Data
Before data preparation, it is essential to have a good understanding of the data you are working with. This includes understanding the structure of the data and any potential challenges or limitations.
- Handle Missing Values Appropriately
Missing values are a common issue in datasets, and they can cause problems for machine learning models. Therefore, you need to handle missing values appropriately. This can be achieved through imputation (replacing missing values with estimates) or deletion (removing rows or columns with missing values). The best approach will depend on the specific dataset and the objectives of the analysis.
- Remove Irrelevant Data
Not all data is relevant to the problem at hand. Therefore, it is crucial to remove irrelevant data as it can lead to inaccurate predictions and slow down the machine learning model.
- Normalize the Data
Machine learning models often work best when the data is normalized. Normalization is the process of transforming data to have a standardized scale or distribution. This can help to ensure that no one variable has an undue influence on the analysis.
- Split the Data into Training and Testing Sets
It is crucial to split the data into training and testing sets. The training set is used to train the model, while the testing set is used to evaluate its performance. This can help to prevent overfitting (when the model performs well on the training data but poorly on new data) and ensure that the model is generalizing well.
Data preparation is an essential step in the machine learning process. By properly preparing data, you can improve the accuracy and efficiency of your machine learning models, and ensure that they produce reliable and accurate predictions. By following best practices such as understanding your data, handling missing values appropriately, removing irrelevant data, normalizing the data, and splitting the data into training and testing sets, you can set yourself up for success in your machine learning endeavors.